Aggregation
Available since version 0.2.21 onwards
Aggregation is a special type of router used to perform aggregation type of operation across all the nodes in the cluster.
It is used to fan-out requests to all the nodes in the cluster, collect the response and aggregate their the responses.
Aggregations can be used with all functions that exhibit both associative and commutative property like Sum / Product / TopK etc. It's conceptually similar to doing reduce individually on all the nodes and doing a global reduction on those reduced results.
Implementation Details
Aggregation in Suuchi makes use of Twitter Algebird's Aggregator
to represent how we can aggregate the results of all service calls. In short Aggregation is presented as a PartialFunction[MethodDescriptor[ReqT, RespT], Aggregator[RespT, Any, RespT]].
Example of an Aggregation that represent SumOfNumbers can be defined as follows
class SumOfNumbers extends Aggregation {
override def aggregator[ReqT, RespT] = {
case AggregatorGrpc.METHOD_AGGREGATE => new Aggregator[Response, Long, Response] {
override def prepare(input: Response): Long = input.getOutput
override def semigroup: Semigroup[Long] = LongRing
override def present(reduced: Long): Response = Response.newBuilder().setOutput(reduced).build()
}.asInstanceOf[Aggregator[RespT, Any, RespT]]
}
}
We compose this Aggregation with Server abstraction as follows
Server(...)
.aggregate(allNodes, new SuuchiAggregatorService(new SumOfNumbers), new SumOfNumbers)
.start()
SuuchiAggregatorService filters all even numbers from the store and does a local aggregation of the sum. These sums
are then globally summed again at the co-ordinator (node that recieves the request for aggregation) node and the result
is sent back as a response back to the client.
Distributed Sum Example
Let's consider an example where we would like to find a sum of all even numbers we have on each node. The entire flow of data on each node and the co-ordinator node is depicted below in the diagram.
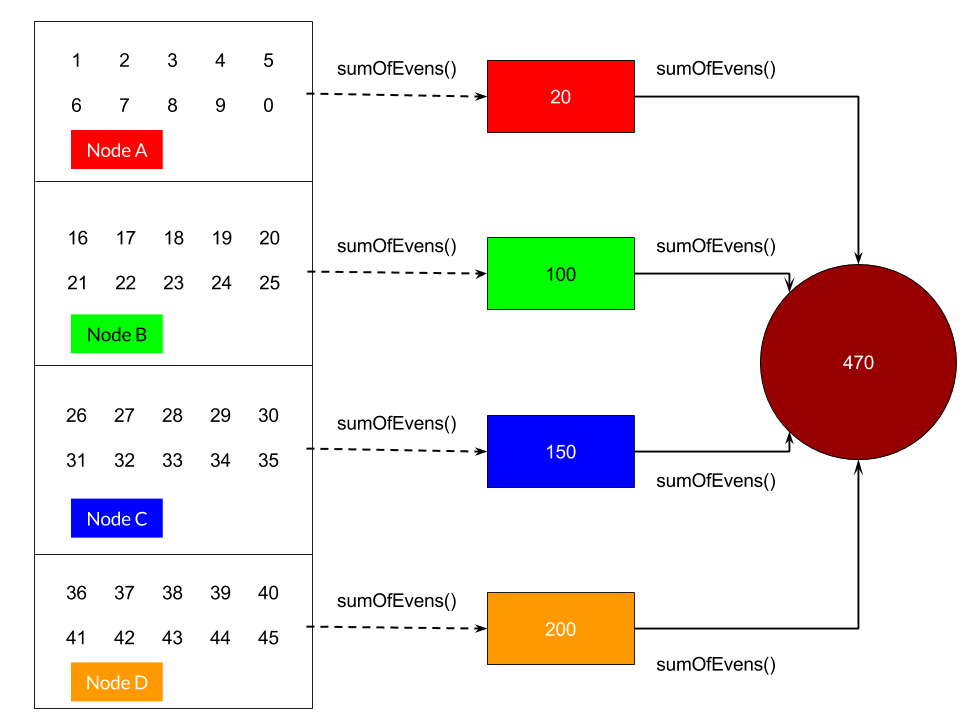
Assume we've 4 nodes Node A - D, and each of them contain a set of numbers with them. The cost of doing filter and sum on each node if very efficient then returning all the numbers to a single node, filtering them and then computing the sum. This in traditional computer architectural terms is called as function shipping paradigm, very similar to stored procedures in RDBMS.